Muszę Cię rozczarować – nie ma na to prostej odpowiedzi czy złotej uniwersalnej rady. Analiza danych nie jest łatwa, prosta i przyjemna, ponieważ składa się na nią wiele czynników. Bardzo pomaga znajomość statystyki, bo wtedy nabieramy nieco dystansu do tych cyferek.
Jednak postaram się podrzucić parę wskazówek, które pomogą Ci podejmować lepsze decyzje w oparciu o dane z Google Analytics.
Zdobądź podstawową wiedzę o analizie danych
To może być nieco zniechęcające, ale jeśli tutaj jesteś to znaczy, że chcesz się do tematu zabrać na serio. Więc oto kilka nieco gorzkich słów prawdy.
Gorąco polecam znalezienie kursu dla siebie, który pomoże nam zdobyć podstawową wiedzę o analizie danych, jak czytać wykresy, tabele, co to jest błąd statystyczny i dlaczego dane, które warto analizować zaczynają się od 100 (oczywiście upraszczając!). Ostatnio za łatwo zostać analitykiem i nie mam tutaj na myśli tego, że jest to wiedza tajemna tylko dla wybranych, a to, że ludzie uważają, że analizują dane porównując dwie średnie do siebie. To trochę tak, jakby umiejętność zrobienia kanapek czyniła Cię kucharzem.
Analiza danych nie jest łatwa, ani na podstawowym, ani na zaawansowanym poziomie. Wymaga mnóstwo uważności, dyscypliny i upewniania się czy nie wysuwamy bezpodstawnych wniosków. To, że lubisz matematykę, że dobrze Ci szła w szkole to jeszcze nieco za mało. Sięgnij po kurs (albo poproś jakiegoś chata AI), który obejmie takie zagadnienia jak:
- Statystyka i testowanie hipotez. Sama średnia i mediana to dopiero początek. Musisz wiedzieć, czy różnica, którą widzisz, jest dziełem przypadku, czy istotnym trendem.
- Czyszczenie i przygotowanie danych. Tutaj myślę, że wystarczy świadomość, że wartości odstające potrafią mocno zaburzyć finalne wyniki i wyrobienie sobie intuicji odnośnie braków danych, czyli czego nie wiemy, aby wysunąć jakiś wniosek.
- Korelacja, a przyczynowość. Najgorszy wróg każdego, nie tylko analityka. Więcej pisałam o tym tutaj, ale zachęcam Cię do zastanawiania się zawsze czy może być jakaś przyczyna, o której nie wiemy albo nie ma jej w danych. To, że sprzedaż lodów rośnie wraz z liczbą utonięć, nie oznacza, że lody powodują tonięcie (po prostu w obu przypadkach jest lato)
- Krytyczne myślenie i błędy poznawcze. Bardzo powiązane z poprzednim punktem. Mózg nas oszukuje cały czas i szuka powiązań za wszelką cenę. Analityka polega między innymi na tym, żeby podważać swoje własne hipotezy i szukać luk w rozumowaniu. Nie jest to łatwe, ale bardzo ważne. Chłodne spojrzenie na dane może uratować Cię od zbyt daleko idących wniosków.
Nie potrzebujesz uczyć się SQL, Pythona czy R na tym etapie. Najpierw naucz się czytać tabelki w GA4 i szukać w danych dziur 🙂 Największym błędem jest zbyt silna wiara w to, że liczby nie kłamią. Liczby są szczere, ale kontekst często bywa iluzją, którą my sobie dopowiadamy.
I pamiętaj: efekt Dunninga Krugera dotyczy nas wszystkich, niestety.
Poniżej znajdziesz parę wskazówek dotyczących konkretnie GA4.
Poznaj dobrze źródło swoich danych, czyli jakie błędy zawiera Google Analytics?
O tym już pisałam co nieco tutaj: Najgorszy błąd poznawczy, który może zrujnować Twój biznes, ale o tym nigdy dość. Nie ma co się czarować – Google Analytics to dobre narzędzie, ale nigdy nie da Ci w 100% pełnego obrazu rzeczywistych zachowań użytkowników na stronie. Żadne inne narzędzie także nie. Nie tylko dlatego, że mamy politykę prywatności i ktoś może odmówić zbierania o nim danych w ciasteczku, ale też dlatego, że nie wszystko da się śledzić. I jako odbiorca danych musisz mieć świadomość jakie są potencjalne niewiadome oraz to jakie te dane mają słabości.
Czy możemy w 100% ufać danym z narzędzi do śledzenia użytkowników?
W Google Analytics możesz zbierać informacje o akcjach takich jak dodanie do koszyka, przewijanie, czy wysłanie formularza, jednak na tej podstawie nigdy nie będziesz wiedzieć co użytkownicy mają w głowach. Ważne jest to, aby sobie tego nie dopowiadać i nie traktować potem tych naszych pomysłów jako jedynej słusznej prawdy. Np. to, że ludzie z naszej strony wychodzą nie oznacza od razu, że UX jest zły albo treść nieciekawa. Może to najnormalniej w świecie być przypadkiem. Wychodzą, bo skończyła im się przerwa w pracy, bo ziemniaki zaczęły kipić i musieli lecieć ratować sytuację i tym podobne prozaiczne sprawy. Warto mieć z tyłu głowy, że część danych, które otrzymujesz jest wynikiem losowości, jakiegoś przypadku. To nie znaczy, że te dane są do kosza. Po prostu nie powinno się przykładać do nich aż tak dużej wagi.
Na przykład, gdy widzimy, że jest duża różnica pomiędzy liczbą wydarzeń form_start, a form_submit to jest bardzo dużo powodów, dla których ludzie opuszczają wypełnianie formularza. Cześć z nich możemy wymyślić albo jest oczywista, ale musimy mieć też świadomość, że będzie wśród nich wiele powodów, które nie przyjdą nam do głowy.
Podczas badań na użytkownikach miałam okazję obserwować jak ludzie tak na żywo sobie przeglądają różne strony i aplikację. I jest to zazwyczaj czysty chaos. Ważne jest, aby mieć świadomość tego jak wiele danych płynących ze śledzenia użytkowników jest nieco losowych. Zwróć uwagę na to jak Ty zachowujesz się na innych stronach przeglądając internet. Ile razy klikniesz coś przypadkiem, ile razy wyjdziesz, a potem wrócisz, a potem jednak i tak zrezygnujesz itd.
Tak więc krótka odpowiedź na pytanie z akapitu: NIE, ale to nic złego. Po prostu trzeba o tym pamiętać.
Dane to nie gotowe odpowiedzi, to wskazówki
Dane w GA4 nie są wyrocznią, nie są po to, żeby powiedzieć Ci co masz robić. Dane są po to, abyś mógł przetestować hipotezę. Np. masz jakiś pomysł, który może podnieść konwersję na stronie – super. Dane są po to, aby pomóc Ci zadecydować, czy ta zmiana była dobra czy nie i czy ją zostawiasz.
Przejdźmy teraz do kolejnego rozwijania wątpliwości 🙂
Jeśli wyniki są ZBYT dobre, to prawdopodobnie są błędne lub niewiarygodne.
Niestety, ale jeśli np. jest spory, nieuzasadniony żadnymi działaniami pik w danych, to prawdopodobnie jest to spam (lub boty narzędzia Consent Mode Platform np. Cookiebot). Zdarza się, że niektóre firmy oferujące działania spamerskie w ten sposób reklamują swoje usługi. Zdarza się także, że agencje wykupują takie działania, aby sztucznie podkręcić dane i przedstawić lepsze wyniki. Teoretycznie Analytics odfiltrowuje taki ruch, ale nie zawsze mu się to udaje. Taki ruch będzie miał bardzo mały czas przebywania na stronie (nawet < 0:00:01) i zazwyczaj się nie powtórzy. Będzie w jednym dniu, nawet w jednej godzinie i tyle.
Pik związany z faktycznym zainteresowaniem (np. jakiś influencer spontanicznie nas polecił) będzie stopniowo malał.
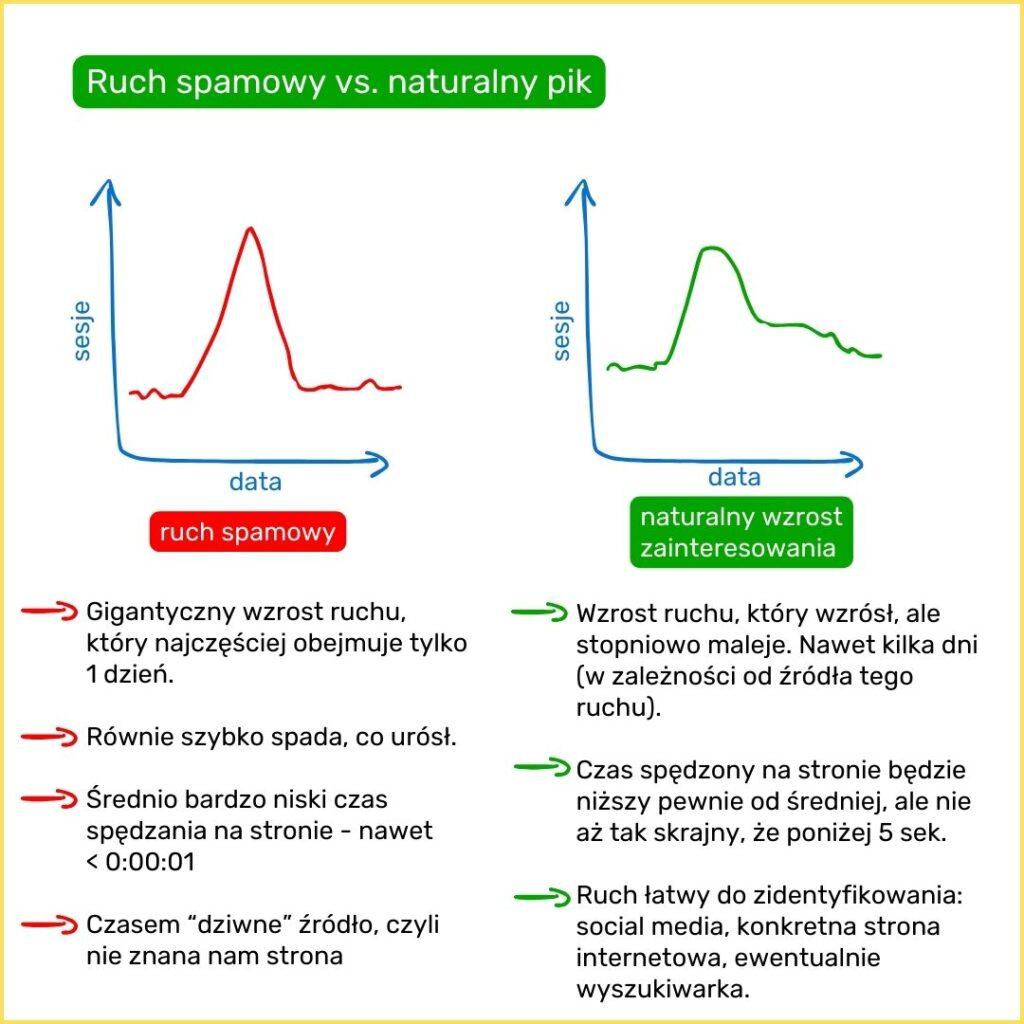
Takich ruch możemy odfiltrowywać albo w Lookerze albo tworząc w Analytisie grupę z kryteriami wykluczającymi ten ruch (na górze Dodaj porównanie) lub w Eksploracjach (zakładka Odkrywaj) tworząc osobny segment. Niestety nie da się tak jak w UA (starej wersji GA4) odfiltrowywać tego ruchu na stałe.
Zdarza się także, że wzmożony ruch wyglądający jak naturalny (rozciągnięty w czasie) pojawił się jako Direct (bezpośrednie wejścia) – tutaj warto sprawdzić kraje. Widziałam na niektórych kontach GA4 taki ruch z Chin pod koniec 2025 roku. To prawdopodobnie boty skanujące treści, niestety. W ogóle ruch z Direct jest najtrudniejszym do analizy, ponieważ tam wpada wszystko co nie jest przypisane do konkretnego źródła lub ma zgubione źródło. Tam także wpadają realni użytkownicy, którzy doskonale znają naszą markę i regularnie powracają. Więc do Direct wpada najlepszej i najgorszej jakości ruch. Z tego powodu zwykle pomijam go w analizie.
Dane napływają z opóźnieniem i są przetwarzane.
Niestety to jest coś co przeszkadza, szczególnie, gdy byliśmy przyzwyczajeni do poprzedniej wersji Analyticsa. Dane, które spływają w czasie rzeczywistym widzimy z ograniczeniami, a na wszystkie dane z dnia musimy poczekać często ponad 24h.
Czy jest to duża niedogodność? To zależy, ale w momencie testowania nowych rozwiązań podgląd ruchu na żywo pozwalał na weryfikację, czy na pewno wszystko jest w porządku. Trzeba brać to pod uwagę i wdrażać być może ostrożniej. Częściowym rozwiązaniem problemu jest oczywiście wbudowany w GA4 tryb debbugowania, o którym pisałam tutaj oraz podglądanie ruchu na żywo.
Dodatkowo dane te zależą od tego jak i czy wdrożyliśmy tryb zgodności (Consent Mode) w kontekście ciasteczek. Zaskakująco sporo stron ma to wdrożone błędnie. Najczęściej ładują ciasteczka przed uzyskaniem na nie zgody, więc banner zbierania zgód jest tylko atrapą i nie działa faktycznie. Jeśli potrzebujesz pomocy w tym temacie to zapraszam do kontaktu. (szczegóły znajdziesz w ofercie pod Audytem dla GA4)
Dane mogą być modelowane. To zależy od Ciebie i możesz ustawić w panelu Administracji, że nie chcesz, aby były modelowane w dowolnym momencie możesz to zmienić – więcej o tych ustawieniach tutaj.
Zdarza się, że błędna implementacja GA4 sprawia, że dane są rozbijane np. na dwa ciasteczka lub GA4 ładuje się za późno i sesję użytkownika zaczyna mierzyć w jej połowie. W ogromnym skrócie: GA4 razem z banerem zgód (ciasteczek) musi się ładować najwcześniej jak się da, a użytkownik musi zareagować na baner zgód, żeby przeglądać stronę. Trochę więcej piszę o tym tutaj, ale błędy w implementacji są tak różnorodne i różnią się w tak drobnych szczegółach, że ciężko opisać je wszystkie.
Czy warto korzystać z AI (ChatGPT, Gemini, Claude itp) do analizy danych?
I tak, i nie. To tylko narzędzia, które możemy wykorzystywać zarówno bardzo skutecznie przyspieszając naszą pracę, ale także sabotując ją. To jak zdolny stażysta, który okłamie Cię prosto w oczy, byle tylko przygotować rozbudowaną gotową odpowiedź. Pozornie zawsze to ma sens i wygląda na pierwszy rzut oka rewelacyjnie, jak większość obrazków AI. Jednak jak się przyglądniesz, to często jest to dobrze brzmiący bełkot.
W jakich sytuacjach AI to twój sprzymierzeniec?
Pisanie kodu (SQL, Python, R):
Potrafi w sekundy wygenerować szkielet skryptu, który Tobie zająłby pół godziny szukania na Stack Overflow. Genialna sprawa, przyspiesza pracę nad skryptami nieprawdopodobnie, a wdrażanie poprawek i kompilowanie to niemal czysta przyjemność. Tylko i tak potrzebujesz znać podstawy :). Więc dla początkującego analityka niestety niezbyt przydatne.
Wyjaśnianie terminów, definicji – encyklopedia i podręcznik:
Trzy razy tak. Zamiast szukać sensownych materiałów – pytasz i masz. Możesz pytać o trudne zagadnienia tak, żeby Ci wyjaśnił jak przedszkolakowi. Proste i genialne. Wie większość i rzadko się myli, bo właśnie do tego jest stworzone, czyli do szukania informacji w swoich zasobach, a nie do myślenia (jak większość ludzi podchodzi do tych narzędzi. Modele językowe mogą mieć zaawansowane funkcje, które symulują myślenie, ale nie traktuj tego jako prawdziwą sztuczną inteligencję lepszą od człowieka pod każdym względem. Na potrzeby tego wpisu uznajmy, że to bardziej jak super zaawansowana encyklopedia i najlepiej tak z niej korzystać.
Niestety nie zawsze sobie radzi z poradami dotyczącymi GA4 lub Lookera. Bardzo często gada bzdury, ponieważ odnosi się do przestarzałych informacji o Universal Analytics (starej wersji Google Analytics). A jeśli chodzi o Lookera to już w ogóle potrafi mocno odlecieć.
Szybkie prototypowanie:
Jeśli utkniesz i nie wiesz czego potrzebujesz to jest świetne narzędzie do odblokowania przestoju i zainspirowania się.
- Nie wiesz gdzie są jakieś informacje? Na pewno Ci pomoże.
- Nie wiesz jak zwizualizować jakieś dane? Proszę bardzo.
- Nie wiesz co masz dalej zrobić z tymi danymi? Nawet jak podpowie coś średnio przydatnego to potrafi odblokować kreatywność i pomóc Ci samemu wpaść na pomysł.
- Nie wiesz od czego zacząć dany projekt? Potrzebujesz szybkiego prototypu czegokolwiek? Nawet jak wyrzuci coś całkiem nie takiego co potrzebujesz to przynajmniej dowiesz się czego nie wiesz i czego chcesz konkretniej.
Jako doradca kreatywny może być niezastąpione. Tylko powinno być Twoim kopilotem, a nie pilotem. Ty trzymasz stery, ponieważ Ty znasz cel podróży i to finalnie Ty ponosisz odpowiedzialność za to, czy wylądujecie na pasie, czy w szczerym polu.
A w jakich największy wróg?
Poczucie fałszywego bezpieczeństwa:
Największym problemem jest nasza wiara w to co wypluwają te modele. Bardzo często są to świetne rzeczy, pomysły, możliwości, które realnie nam pomagają. To daje nam też poczucie bezpieczeństwa, bo nasz mózg to leniwa bestia. Jeśli ktoś wzbudza nasze zaufanie lub już mu przypniemy łatkę eksperta to rzadko kiedy zastanawiamy się nad tym ponownie. Raz ustalony status często nie jest podważany, dopóki nie wydarzy się znaczący błąd. Ta nasza cecha sprawia, że jak Chat GPT (czy inny) nas nie zawodzi podczas podpowiadania nam przepisów kulinarnych oraz odpowiadaniu na najgłupsze pytania jakie przyjdą nam do głowy, to jest duża szansa, że uwierzymy mu także w zaawansowaną analizę danych.
Poczucie bezpieczeństwa przy korzystaniu z wiedzy takich narzędzi sprawia, że stajemy się bezkrytyczni. A jak nie rozumiesz kodu, który stworzyło AI, nie masz nad nim kontroli i nie wiesz czy nie ma tam rzeczy, których nie chcesz, żeby były.
Jeśli nie umiesz czegoś, nie znasz się na czymś, to taki czat wciśnie Ci największą głupotę, ale poda to w taki sposób, że wyda Ci się to prawdopodobne. I to jest ogromne zagrożenie w analizie danych z pomocą takich narzędzi.
Halucynacje:
Tu gładko przechodzimy do tego, co już wspomniałam. Te narzędzia mają za zadanie przede wszystkim Cię zadowolić. Sprawić, że wrócisz po kolejną odpowiedź. Więc dostarczą odpowiedź choćby była wymyślona. Trochę jak człowiek, który nie chce stracić autorytetu i nie powie, że czegoś nie wie.
Modele potrafią zmyślić korelacje (dosłownie może jej nie być w danych) lub błędnie zinterpretować, zachowując przy tym ton eksperta. Niestety bardzo łatwo uwierzyć w te „wnioski”, ponieważ narzędzie robi ciężką robotę (myślenie i analizowanie jest bardzo energochłonne dla naszego mózgu) za nas. Odczuwamy ulgę, że najtrudniejsze za nami, więc nie zastanawiamy się czy wnioski stały obok prawdy wystarczająco blisko. Im trudniejsze zagadnienie, tym większa szansa na halucynacje i tym także większe nasze „lenistwo” w podważaniu tego co zostało wyplute przez AI. Niestety bardzo często drogi na skróty nie istnieją.
Dodatkowo narzędzia lubią dodać coś od siebie zbaczając z tematu (pamiętajmy, że to są przede wszystkim modele językowe, które składają zdania jak puzzle, a nie realnie myślą) i przedstawiając komuś raport z takimi wnioskami z AI możemy wypaść głupio 😉
Brak kontekstu biznesowego:
Kontekst biznesowy, ludzki, struktura firmy, produktów i ich specyfika jest zazwyczaj AI nieznana. Narzędzie interpretuje dane, które mu wrzucisz, ale bez wiedzy, którą masz, że np. ten nagły skok w danych to nie „trend wzrostowy”, tylko jednorazowa promocja, o której wiedzą tylko ludzie w Twoim biurze. Natomiast jak już pisałam wcześniej łatwo uwierzyć w te wnioski, bo są podane na tacy.
Dlatego ciężko mi uwierzyć w wszelkie narzędzia, które przeanalizują GA4 za Ciebie. Wizualizacje danych – jak najbardziej, ale interpretacja? Niekoniecznie. Szczególnie, jeśli jesteś osobą, która o analizie i samym GA4 nic nie wie. To może być duża pułapka, bo nie wiesz czego nie wiesz i nie wiesz czego nie wie AI, a co jest kluczowe do jakiegokolwiek wnioskowania. Bo często zanim zaczniemy wnioskować to musimy znać „otoczenie” danych.
Przykład:
Biznes usługowy, wycena jest uzależniona od nakładu pracy (dość liniowo). Część ludzi wypełnia formularz, część pisze maila, część dzwoni. Część jest klientów firmowych, część prywatnych. Najwięcej danych jest z formularza i tam jest największy współczynnik konwersji. Do CRM jest wprowadzany parametr gclid i na tej podstawie wiemy, który formularz jest z reklamy i jaką ma wartość.
Gdy zapytasz Gemini (i pewnie inne modele też): Jaka kampania reklamowa i z jaką optymalizacją w Google Ads będzie najskuteczniejsza dla tego biznesu?
Odpowie, że kampania Search i optymalizacja pod maksymalizacje wartości konwersji wprowadzanych offline z docelowym ROAS. Dzięki temu Google będzie licytować agresywniej o klienta firmowego (duże zlecenie), a odpuści klienta prywatnego, który szuka najtańszej opcji, jeśli przewidywana wartość zlecenia jest niska.
I ma to sens. Tylko pojawiają się 3 problemy:
- Tylko, że Gemini nie wie, że najlepsze zlecenia firmowe wpadają Ci przez maila i nie jesteś w stanie powiązać skąd dany mail przyszedł (z której kampanii) i jaką przyniósł wartość. To, że formularz ma największy współczynnik konwersji nie oznacza, że tak naprawdę jest, tylko, że to jesteśmy w stanie odnotować. Nie jesteśmy w stanie odnotować, że ktoś wpisał sobie maila z pamięci lub przepisał ręcznie. Więc formularz ma nadreprezentację mniej opłacalnego klienta prywatnego, a przez ograniczenia techniczne wprowadzasz dane świadczące o sukcesie kampanii TYLKO z formularza. Wprowadzamy do algorytmu tylko to, co udało się zmierzyć, a nie to, co faktycznie zarobiło pieniądze. Efekt może być taki, że reklamy przestaną pojawiać się firmom, bo algorytm uznał je za „niekonwertujące”. A wprowadzane dane będą potwierdzać tę tezę (bo wprowadzamy tylko to co mierzymy, czyli głównie klienta prywatnego), mimo że rzeczywistość biznesowa jest odwrotna.
- Gemini nie wie też, że wiele z formularzy nie staje się zleceniami (z różnych powodów), więc jeśli optymalizujesz kampanię na wartość zleceń, to tych danych jest bardzo mało. Algorytmy typu Value-Based Bidding (tROAS) potrzebują setek konwersji miesięcznie, by zrozumieć wzorzec. Jeśli „duże zlecenia” zdarzają się rzadko i nieregularnie, algorytm nie znajdzie reguły i zacznie „panikować”.
- Finalnie Gemini nie wie, że wartość zlecenia nie zależy tak naprawdę od niczego i nie masz persony klienta, to może być każdy i każda firma. Nie ma tutaj reguły, że jeśli ktoś wpisze dane słowo kluczowe lub szukał jakiś innych rzeczy, to wtedy będzie wartość zlecenia wyższa lub niższa. Tam gdzie Ty nie widzisz zależności i ciężko opracować Ci idealną personę dla biznesu, to algorytm nie ma szklanej kuli, która to wymyśli.
To sprawia, że optymalizacja pod maksymalizacje liczby konwersji będzie lepsza dla tego biznesu, bo nie zawęża lejka na samej górze (bo nie ma podstaw do jego zawężenia) i podnosi szanse na wyłapanie dużego zlecenia. Optymalizacja pod wartość (tROAS) przy niepełnych danych to próba sterowania statkiem za pomocą kompasu, który reaguje tylko na metalowe przedmioty na pokładzie, a ignoruje pole magnetyczne ziemi. Maksymalizacja liczby konwersji oznacza, że każde zapytanie to szansa, a proces odsiewu ziarna od plew zostawia człowiekowi, zamiast pozwolić AI (czyli algorytmowi, który przewiduje, który użytkownik dowiezie najwyższy ROAS) uciąć dopływ potencjalnych klientów już na samym starcie. Czasem 'więcej’ (maksymalizacja konwersji) znaczy bezpieczniej niż 'precyzyjniej’ (maksymalizacja wartości), gdy ta precyzja opiera się na błędnych założeniach.
Jest taka zasada w świecie danych garbage in, garbage out, która mówi o tym, że jeśli wprowadzimy błędne dane, mamy błędne założenia, to niestety wnioski też będą błędne. Dlatego jakość wprowadzanych danych do algorytmów reklamowych (jak Google Ads) powinna być jak najwyższa.
Do podsumowania tych wniosków i pomocy przy opisaniu problemów posłużyłam się Gemini, żeby pomógł mi lepiej (lub inaczej) opisać to o co mi chodziło. Bo AI nie jest złe. Tylko trzeba je wykorzystywać jak każde inne narzędzie, a nie realnego człowieka 🙂
Podsumowanie dla niecierpliwych (tl;dr):
Analiza danych to balansowanie między tym, co pokazują liczby, a tym, co podpowiada Ci intuicja i znajomość ludzkich zachowań. Jeśli masz zapamiętać tylko trzy rzeczy, niech to będą te:
- Pokora ponad pewność siebie: Jeśli dane wyglądają zbyt pięknie, by były prawdziwe, prawdopodobnie patrzysz na błąd wdrożeniowy lub ruch botów. Niestety im mniej wiemy o statystyce, tym łatwiej o zero-jedynkowe (i błędne) wnioski.
- Mierz to, co ważne, a nie to, co łatwe: Nie daj się złapać w pułapkę optymalizacji pod „mierzalne resztki” (jak tylko formularze), ignorując realne źródła dochodu (jak maile), których nie mamy możliwości mierzyć tak dokładnie. Szczególnie, gdy wielu z Twoich klientów kontaktuje się mailowo lub telefonicznie. To realni ludzie są ważni, a nie cyferki w GA4.
- AI to Twój stażysta, a nie dyrektor: Korzystaj z ChatGPT do pisania kodu czy definicji, ale nigdy nie oddawaj mu sterów przy interpretacji biznesu. AI nie wie wszystkiego, a Ty nie jesteś w stanie wszystkiego mu przekazać.
Zacznij od podważania własnych założeń. Szukaj dziur w całym, pytaj „Czego te dane mi NIE MÓWIĄ?” i zaakceptuj fakt, że liczby to tylko drogowskazy, a nie gotowa mapa. Droga do rzetelnej analizy jest wyboista, ale to jedyna droga, która nie prowadzi na biznesowe manowce 😉